
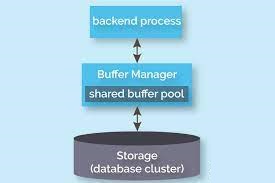
Shared Buffers
It is in every case quicker to peruse or compose information in memory than on some other media. A data set server likewise needs memory for speedy admittance to information, whether it is READ or WRITE access. In PostgreSQL, this is alluded to as “shared cradles” and is constrained by the boundary shared_buffers. How much RAM expected by shared supports is constantly locked for the PostgreSQL case during its lifetime. The common cradles are gotten to by all the foundation server and client processes interfacing with the information base.
The information that is composed or altered in this area is classified “grimy information” and the unit of activity being data set blocks (or pages), the changed blocks are additionally called “messy blocks” or “filthy pages”. In this manner, the messy information is set up to circle containing actual records to account the information in determined area and these documents are classified “information documents”.
WAL Buffers
The compose ahead log (WAL) supports are likewise called “exchange log cradles”, which is a measure of memory designation for putting away WAL information. This WAL information is the metadata data about changes to the genuine information, and is adequate to remake genuine information during data set recuperation tasks. The WAL information is kept in touch with a bunch of actual records in persevering area called “WAL portions” or “designated spot fragments”.
The WAL supports memory distribution is constrained by the wal_buffers boundary, and it is assigned from the working framework RAM. Albeit this memory region is likewise open by all the foundation server and client processes, it isn’t essential for the common supports. The WAL cushions are outside to the common cradles and are tiny when contrasted with shared supports. The WAL information is first altered (dirtied) in WAL cradles before it is kept in touch with WAL sections on plate. On the off chance that it is passed on to default settings, it is dispensed with a size of 1/sixteenth of the common cradles.
Obstruct Buffers
Obstruct means “commit log”, and the CLOG supports is a region in working framework RAM devoted to hold commit log pages. The commit log pages contain log of exchange metadata and vary from the WAL information. The commit logs have commit status of all exchanges and demonstrate whether an exchange has been finished (dedicated).
There is no particular boundary to control this area of memory. This is naturally overseen by the data set motor in little sums. This is a common memory part, which is open to all the foundation server and client cycles of a PostgreSQL data set.
Memory for Locks/Lock Space
This memory part is to store all heavyweight locks utilized by the PostgreSQL example. These locks are shared across all the foundation server and client processes associating with the information base. A non-default bigger setting of two data set boundaries specifically max_locks_per_transaction and max_pred_locks_per_transaction in a manner impacts the size of this memory part.
Vacuum Buffers
This is the greatest measure of memory utilized by each of the autovacuum laborer cycles, and it is constrained by the autovacuum_work_mem information base boundary. The memory is apportioned from the working framework RAM and is likewise impacted by the autovacuum_max_workers data set boundary. The setting of autovacuum_work_mem ought to be designed cautiously as autovacuum_max_workers times this memory will be apportioned from the RAM. This large number of boundary settings possibly become possibly the most important factor when the auto vacuum daemon is empowered, in any case, these settings affect the way of behaving of VACUUM when run in different settings. This memory part isn’t shared by some other foundation server or client process.
Temp Buffers
A data set might have at least one brief tables, and the information blocks (pages) of such transitory tables need a different distribution of memory to be handled in. The temp supports fill this need by using a part of RAM, characterized by the temp_buffers boundary. The temp supports are just utilized for admittance to impermanent tables in a client meeting. There is no connection between temp cradles in memory and the brief records that are made under the pgsql_tmp catalog during enormous sort and hash table tasks.